Evals Driven Development
Open Agents Builder – Evaluation Framework Documentation
Welcome to the step-by-step guide that shows you how to generate, edit and run automated evaluation tests (“Evals”) for any agent you build with Open Agents Builder. The screenshots below come from the video walkthrough and illustrate each phase of the workflow.
1. Why Evals Matter
| ✔️ What they give you | :x: What happens without them |
|---|---|
| Confidence your agent still behaves as intended after every prompt tweak, tool-addition or API upgrade. | Silent regressions—something that used to work breaks and no one notices until a user reports it. |
| A “unit-test-like” safety net that developers already expect in traditional software development. | Tedious manual testing of every flow before each deployment. |
| Rapid iteration—you ship new features faster because you can instantly verify that the core logic remains green. | Fear of refactoring or adding new capabilities. |
2. Prerequisites
- A free Open Agents Builder account – creating one takes ~3 minutes at https://openagentsbuilder.com
- An agent template you can experiment with. In the demo we used “Bella Styles – Hairdresser booking”.
3. Creating (or Opening) an Agent
- Log in and click “New Agent…” or pick an existing template.
- Complete any initial onboarding fields (name, e-mail, etc.).
- Verify the basic conversation flow works (e.g. ask for available slots).
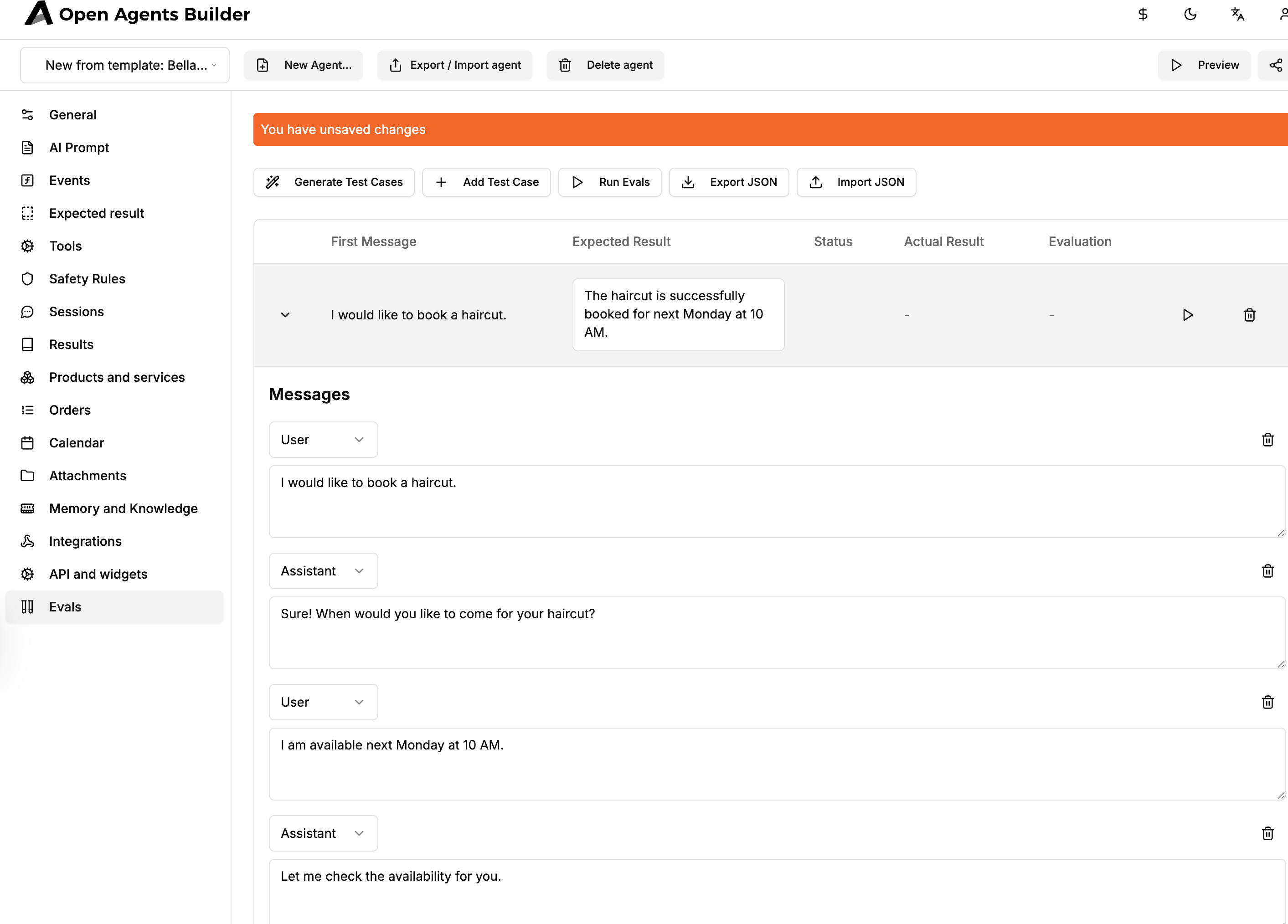
4. The “Evals” Tab
Once the agent loads, notice the new “Evals” tab in the left rail. Click it to open the evaluation dashboard.
Key columns:
- First Message – the utterance that starts the scripted conversation.
- Expected Result – what should happen (assistant reply, booked time, tool calls, etc.).
- Status / Actual Result / Evaluation – populated after a test run.
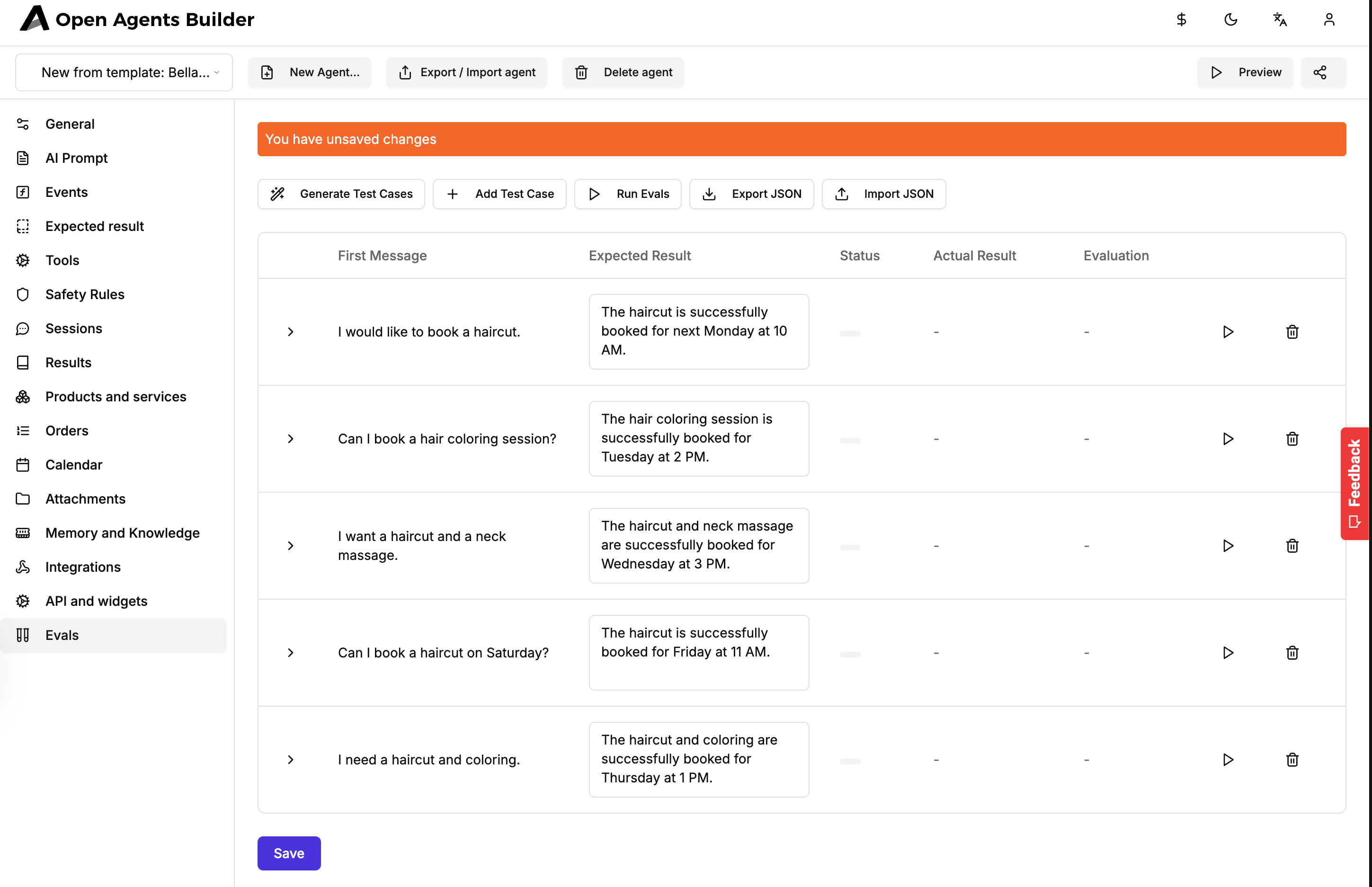
5. Generating Test Cases Automatically
- Press “Generate Test Cases”.
- The system analyses your AI Prompt and synthesises representative user journeys—haircut, colouring, combined services, weekend bookings, etc.
- In a few seconds you’ll see multiple rows populated, each with a pre-filled Expected Result.
Tips
- Generation is additive—run it again after you expand your prompt to cover new tools or intents.
- You can delete or tweak any case manually.
6. Editing or Adding Test Cases Manually
- Click “Add Test Case” to insert a blank row.
- Fill First Message with the user’s opening line.
- Specify a concise Expected Result written in plain language (what you deem “pass”).
- (Optional) Expand the row to script the full back-and-forth, including expected tool calls.
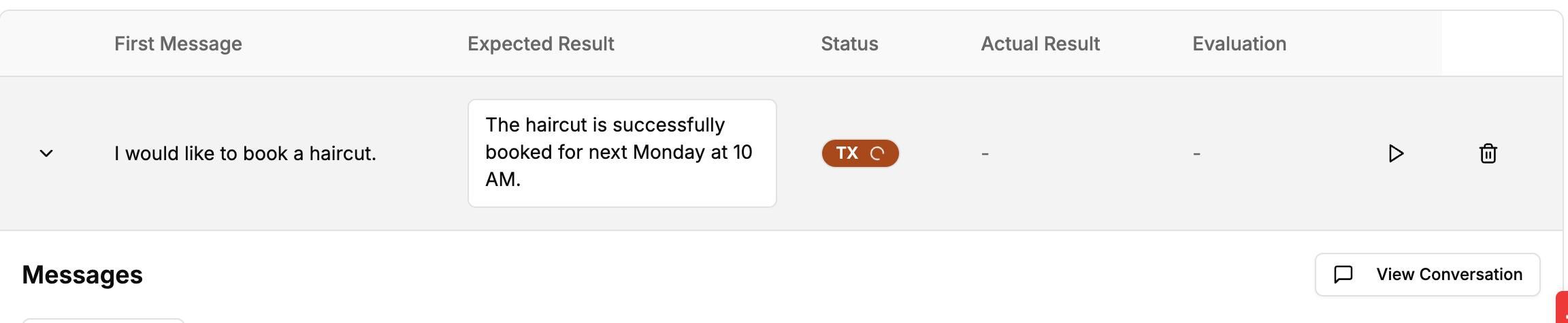
7. Running Evals
There are two ways to execute:
| Button | What it does |
|---|---|
| ▶︎ (inside a row) | Runs one case—handy while iterating. |
| Run Evals (toolbar) | Runs all cases in batch. |
During execution the eval engine “plays” the conversation exactly as a user would, calling tools, parsing responses and asserting expectations.
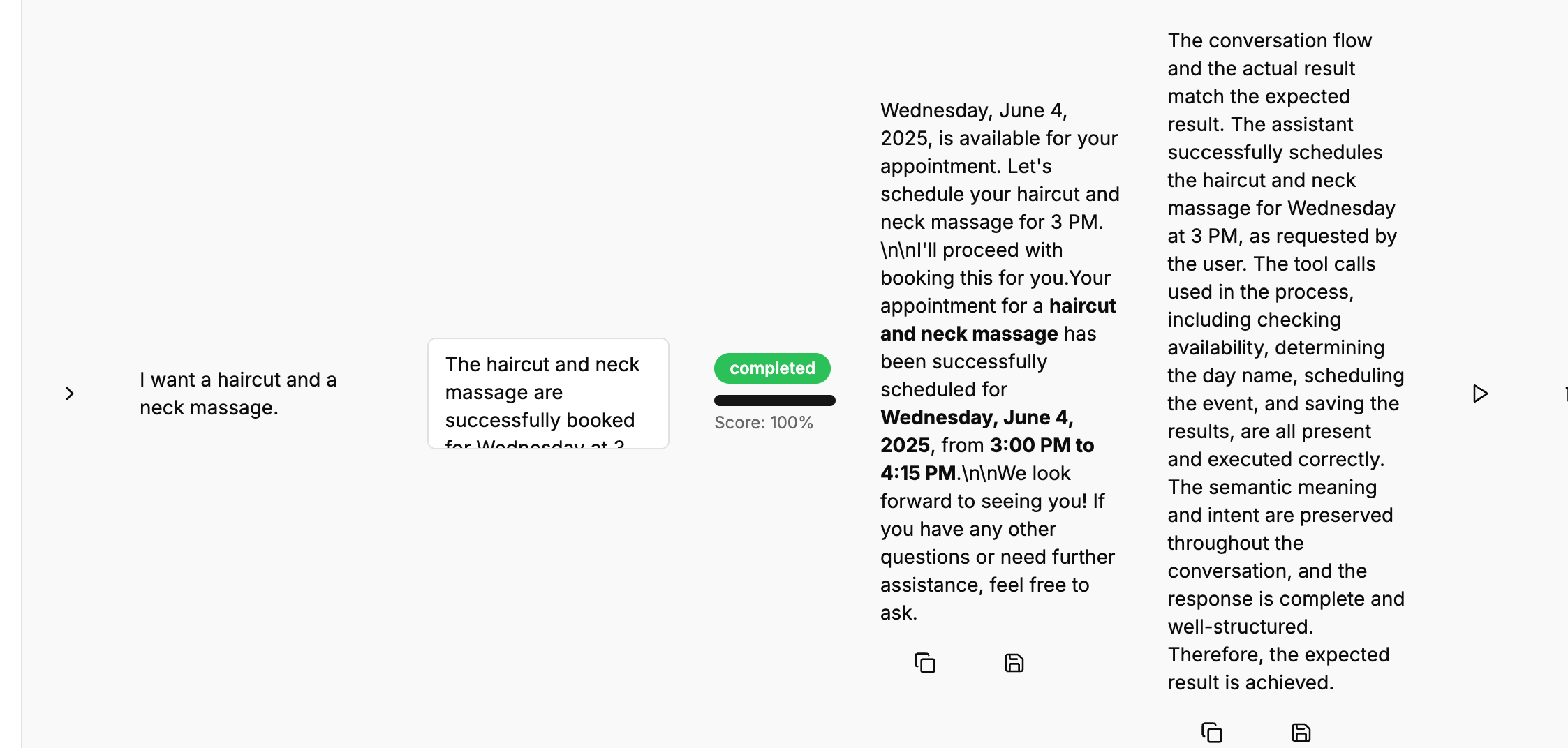
Green “completed” = pass, Red “failed” = mismatch. Click a status pill to expand the full transcript, see every tool call and the evaluation diff.
8. Typical Failure Scenarios & Debugging
| Failure Type | Example (Hair Salon) | Common Fix |
|---|---|---|
| Time-slot already taken | Second run of same haircut test fails because 10 AM Monday is now booked. | Reset test data (e.g. clear mock calendar) before replay, or choose a future dynamic date in the script. |
| LLM phrasing drift | Assistant replies “Sure thing—when works best?” instead of “When would you like to come?”. | Loosen the Expected Result wording, or use regex / key-phrase evaluation if supported. |
| Tool order mismatch | Availability checked after booking call. | Refactor the agent’s logic or adjust the expected-tool sequence. |
9. Exporting & Importing Eval Suites
You can share or version-control your cases:
- Export JSON – downloads the entire suite.
- Import JSON – uploads into any other agent that needs the same behavioural guarantees.
Ideal for teams maintaining multiple agents with similar capabilities.
10. Adjusting test cases
There’s one more usefull tool you might want to use which is “Adjust test case” which adjusts the expected result + conversation flow to actuall results got from the previous evaluation to make sure the test will pass. Be carefull using this feature, always making sure the test still renders the expected reality.

11. Best Practices Checklist
- Green bar rule – merge / deploy only when every eval passes.
- Cover edge cases – cancellations, overlapping appointments, invalid input.
- Reset state between runs (sandbox calendar, mock DB).
- Treat Evals as living docs – update alongside prompt and tool changes.
- Source-control JSON exports to review changes via pull requests.
12. Wrap-up
The Evaluation Framework is your CI-style safety harness for conversational agents:
“Make sure that after each change all the tests are green and the agent works exactly as you wished.”
Start generating your own Evals today, keep them in sync with development, and enjoy bug-free agent releases. Happy building! 🎉